

No epicentro da Quarta Revolução Industrial, a Inteligência Artificial (IA) deixou de ser um conceito de ficção científica para se tornar o motor invisível que impulsiona a economia global. Dentro deste vasto domínio, o Machine Learning (Aprendizado de Máquina) destaca-se como a disciplina técnica responsável por dotar sistemas computacionais da capacidade de aprender com dados, identificar padrões e tomar decisões com intervenção humana mínima.
Para profissionais de tecnologia, cientistas de dados e entusiastas que desejam ir além da superfície, compreender profundamente os tipos de machine learning e os algoritmos de machine learning subjacentes é mandatório. Este artigo oferece uma análise técnica robusta sobre como essas arquiteturas funcionam, diferenciando suas categorias e explorando a matemática e a lógica que as sustentam.
Se você está começando agora e precisa de uma base conceitual antes de mergulhar nos algoritmos, recomendo a leitura do nosso artigo introdutório: Machine Learning Desvendado: Um Guia Essencial para Compreender a IA.
O Que é Machine Learning e a Mudança de Paradigma na Programação
Tradicionalmente, a programação de computadores baseava-se em regras explícitas: “se X acontecer, faça Y”. No entanto, muitos problemas do mundo real — como reconhecimento de voz, diagnóstico médico ou detecção de fraudes — são complexos demais para serem codificados através de regras estáticas. É aqui que entra o aprendizado de máquina.
Como funciona machine learning em termos técnicos? Em vez de programar as regras, alimentamos o computador com dados e um algoritmo que induz as regras por conta própria. O sistema constrói um modelo matemático baseado em amostras de dados (dataset de treino) para fazer previsões ou decisões sem ser explicitamente programado para realizar a tarefa.
Essa abordagem transformou radicalmente a capacidade de processamento de informações, permitindo o surgimento de aplicações que aprendem e evoluem com o tempo. Embora o termo “machine learning para iniciantes” possa sugerir simplicidade, a profundidade matemática envolve estatística, álgebra linear e otimização convexa.
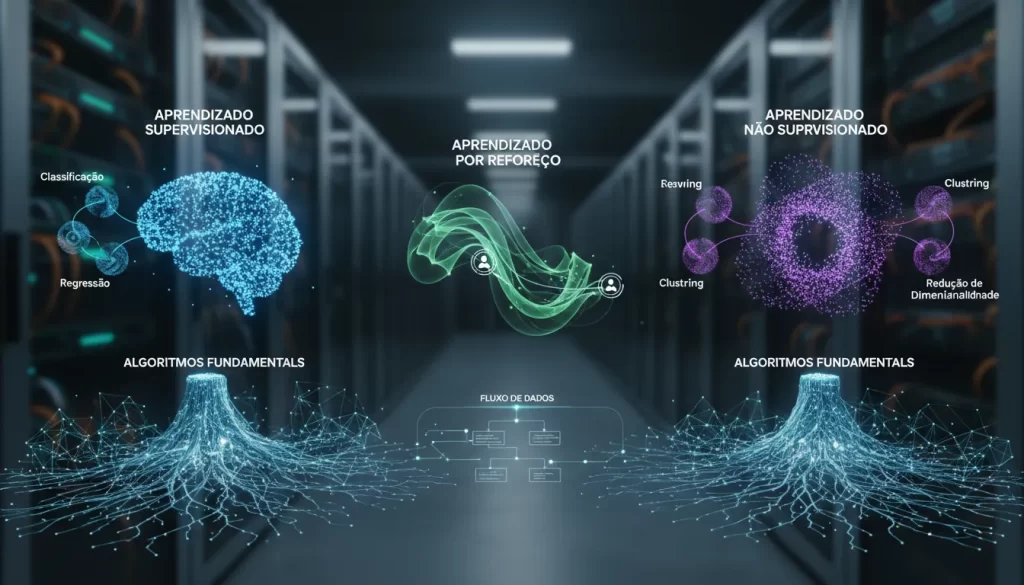
Os Três Pilares: Tipos de Machine Learning
A taxonomia do Machine Learning é geralmente dividida em três categorias principais, baseadas na natureza do sinal de aprendizado ou “feedback” disponível para o sistema de aprendizagem. Compreender esses tipos é crucial para selecionar a abordagem correta para um problema específico.
1. Aprendizado Supervisionado (Supervised Learning)
O aprendizado supervisionado é, atualmente, o tipo mais comum de machine learning aplicado na indústria. Neste paradigma, o algoritmo é treinado utilizando um conjunto de dados rotulados. Isso significa que, para cada entrada de dados fornecida ao algoritmo, também fornecemos a saída correta (o “rótulo” ou “target”).
O objetivo do modelo é aprender uma função de mapeamento que, ao receber novos dados de entrada não vistos anteriormente, possa prever a saída correta com alta precisão. O aprendizado supervisionado divide-se fundamentalmente em dois tipos de problemas:
- Classificação: Quando a variável de saída é uma categoria (ex: “spam” ou “não spam”, “benigno” ou “maligno”).
- Regressão: Quando a variável de saída é um valor contínuo real (ex: prever o preço de uma casa, estimar a demanda de vendas).
2. Aprendizado Não Supervisionado (Unsupervised Learning)
Ao contrário do método anterior, no aprendizado não supervisionado, o algoritmo recebe dados que não possuem rótulos históricos. O sistema não sabe a “resposta certa”. O objetivo aqui é explorar a estrutura dos dados para encontrar padrões ocultos, agrupamentos ou anomalias intrínsecas.
Este tipo é fundamental para a análise exploratória de dados e é frequentemente utilizado em:
- Clustering (Agrupamento): Organizar dados em grupos com base em similaridades (ex: segmentação de clientes).
- Redução de Dimensionalidade: Simplificar os dados comprimindo suas características sem perder informações críticas (ex: PCA – Principal Component Analysis).
- Associação: Descobrir regras que descrevem grandes porções dos dados (ex: “quem compra pão também compra leite”).
3. Aprendizado por Reforço (Reinforcement Learning)
O aprendizado por reforço é o mais próximo de como os seres humanos aprendem: através de tentativa e erro. Neste cenário, um agente interage com um ambiente e aprende a realizar uma tarefa para maximizar uma recompensa acumulada.
Não há um conjunto de dados fixo de entrada-saída. O agente toma uma ação, observa o novo estado do ambiente e recebe uma recompensa (positiva) ou punição (negativa). Com o tempo, o algoritmo (como o Q-Learning ou Deep Q-Networks) desenvolve uma “política” — uma estratégia para determinar a melhor ação a ser tomada em cada estado.
Este é o motor por trás de carros autônomos, robótica avançada e IAs que vencem campeões mundiais em jogos como Go e Xadrez.
Aprofundando nos Algoritmos de Machine Learning
Para entender verdadeiramente a técnica, precisamos dissecar os algoritmos de machine learning mais utilizados. Cada um possui pressupostos matemáticos, vantagens e limitações.
Regressão Linear e Logística
Estes são os algoritmos fundamentais, muitas vezes o ponto de partida para qualquer cientista de dados.
- Regressão Linear: Utilizada para prever valores contínuos. O algoritmo tenta traçar uma linha reta (ou um hiperplano em dimensões superiores) que melhor se ajusta aos pontos de dados, minimizando a soma dos erros quadráticos entre os pontos reais e a linha prevista.
- Regressão Logística: Apesar do nome, é usada para classificação binária. Ela utiliza a função sigmoide para transformar a saída em uma probabilidade entre 0 e 1, ideal para determinar a chance de um evento ocorrer (sim/não).
Árvores de Decisão e Random Forests
- Árvores de Decisão (Decision Trees): Modelos que utilizam uma estrutura de árvore semelhante a um fluxograma. O algoritmo divide os dados em subconjuntos baseados nas características que resultam na maior separação de informações (ganho de informação ou índice Gini). São fáceis de interpretar e visualizar.
- Random Forests (Florestas Aleatórias): Um método “ensemble” (conjunto) que cria múltiplas árvores de decisão durante o treinamento e produz a classe que é a moda das classes (classificação) ou a média das previsões (regressão) das árvores individuais. Isso corrige o problema de “overfitting” (sobreajuste) comum em árvores de decisão únicas, resultando em modelos muito mais robustos e precisos.
Support Vector Machines (SVM)
O SVM é um algoritmo poderoso para classificação e regressão. O objetivo do SVM é encontrar um hiperplano em um espaço N-dimensional (onde N é o número de características) que classifica distintamente os pontos de dados.
O algoritmo busca maximizar a “margem”, ou a distância entre o hiperplano e os pontos de dados mais próximos de qualquer classe (chamados de vetores de suporte). O SVM é extremamente eficaz em espaços de alta dimensão e é versátil devido à sua capacidade de usar diferentes funções de Kernel para tratar dados não lineares.
K-Nearest Neighbors (KNN)
O KNN é um algoritmo simples, porém eficaz, baseado em instâncias. Ele não “aprende” um modelo discriminativo explícito; em vez disso, ele memoriza o conjunto de treinamento. Para fazer uma previsão para um novo ponto de dados, o algoritmo:
- Calcula a distância (geralmente Euclidiana) entre o novo ponto e todos os pontos de treino.
- Seleciona os ‘K’ pontos mais próximos.
- Atribui a classe mais comum entre esses vizinhos (para classificação) ou a média dos valores (para regressão).
Algoritmos de Clustering: K-Means
No campo não supervisionado, o K-Means é o rei. O objetivo é particionar ‘n’ observações em ‘k’ clusters, onde cada observação pertence ao cluster com a média mais próxima (centróide). O algoritmo funciona iterativamente:
- Inicializa aleatoriamente os centróides.
- Atribui cada ponto de dados ao centróide mais próximo.
- Recalcula os centróides com base na média dos pontos atribuídos.
- Repete até a convergência.
Redes Neurais e Deep Learning
Inspiradas na biologia do cérebro humano, as Redes Neurais Artificiais consistem em camadas de nós (neurônios) interconectados. Cada conexão tem um peso que é ajustado durante o aprendizado.
Quando empilhamos muitas camadas ocultas entre a entrada e a saída, entramos no domínio do Deep Learning (Aprendizado Profundo). Esta subárea do Machine Learning é responsável pelos avanços mais notáveis da última década, especialmente em processamento de linguagem natural (NLP) e visão computacional. Algoritmos como Redes Neurais Convolucionais (CNNs) e Redes Neurais Recorrentes (RNNs/Transformers) são capazes de extrair características complexas de dados brutos como imagens e texto.
Aplicações Práticas e Impacto na Indústria
Conhecer os algoritmos é apenas metade da batalha; saber onde aplicá-los é o que gera valor. As aplicações machine learning permeiam quase todos os setores modernos:
- Finanças: Detecção de fraudes em tempo real utilizando Random Forests e Anomalias em transações.
- Saúde: Diagnóstico por imagem utilizando Deep Learning (CNNs) para identificar tumores com precisão superior à humana.
- E-commerce: Sistemas de recomendação (como os da Amazon ou Netflix) que utilizam filtragem colaborativa e fatoração de matrizes.
- Marketing: Segmentação de clientes via Clustering para campanhas personalizadas.
Para uma visão detalhada de como essas tecnologias estão remodelando o mercado, leia nosso artigo completo sobre As Principais Aplicações de Machine Learning que Redefinem Indústrias Atualmente.
Desafios Técnicos: Bias, Variance e Overfitting
Ao trabalhar com algoritmos de machine learning, o profissional enfrenta constantemente o Trade-off entre Viés e Variância:
- Viés (Bias): Erro devido a suposições excessivamente simplistas no algoritmo de aprendizado. Alto viés pode fazer com que o algoritmo perca as relações relevantes entre as características e as saídas (Underfitting).
- Variância (Variance): Erro devido à sensibilidade excessiva a pequenas flutuações no conjunto de treinamento. Alta variância pode fazer com que o algoritmo modele o ruído aleatório nos dados de treinamento, em vez das saídas pretendidas (Overfitting).
O “Santo Graal” do machine learning é encontrar um modelo com baixo viés e baixa variância, que generalize bem para dados nunca vistos.
O Futuro dos Algoritmos
O campo continua a evoluir rapidamente. Estamos vendo o surgimento de AutoML (Machine Learning Automatizado), que busca automatizar a seleção de algoritmos e ajuste de hiperparâmetros, e Explainable AI (XAI), que foca em tornar os modelos de “caixa preta” (como redes neurais profundas) interpretáveis para humanos.
À medida que avançamos, a ética e a responsabilidade no desenvolvimento desses algoritmos tornam-se tão importantes quanto a precisão matemática. Para entender para onde estamos indo, confira nossa análise sobre O Futuro do Machine Learning: Tendências, Inovações e o Impacto na Sociedade.
Conclusão
Dominar os algoritmos e tipos de machine learning exige estudo contínuo e prática aplicada. Desde a simplicidade elegante da Regressão Linear até a complexidade das Redes Neurais Profundas, cada ferramenta tem seu lugar no cinto de utilidades do cientista de dados.
O aprendizado de máquina não é apenas sobre codificação; é sobre entender a natureza dos dados e escolher a arquitetura matemática correta para extrair valor deles. Seja você um estudante buscando machine learning para iniciantes ou um desenvolvedor experiente refinando modelos de produção, a base teórica sólida sobre esses algoritmos é o que diferencia uma implementação medíocre de uma solução transformadora.
A era da inteligência artificial está apenas começando, e o conhecimento profundo dessas estruturas é o passaporte para liderar essa transformação.















